Suppose A is a finite set with n elements. The number of elements and the rank of the largest equivalence relation on A are
ISRO Scientist or Engineer Computer Science Dec 2017
For the following questions answer them individually
Consider the set of integers I. Let D denote “divides with an integer quotient” (e.g. 4D8 but 4D7). Then D is
A bag contains 19 red balls and 19 black balls. Two balls are removed at a time repeatedly and discarded if they are of the same colour, but if they are different, black ball is discarded and red ball is returned to the bag. The probability that this process will terminate with one red ball is
If x = -1 and x = 2 are extreme points of $$f(x) = \alpha \log \mid x \mid + \beta x^2 + x$$ then
Let $$f(x) = \log \mid x \mid$$ and $$g(x) = \sin x$$. If A is the range of $$f(g(x))$$ and B is the range of $$g(f(x))$$ then $$A \cap B$$ is
The proposition $$(P \Rightarrow Q) \wedge (Q \Rightarrow P)$$ is a
If T (x) denotes x is a trigonometric function, P(x) denotes x is a periodic function and C(x) denotes x is a continuous function then the statement “It is not the case that some
trigonometric functions are not periodic” can be logically represented as
The number of elements in the power set of $$\left\{\left\{1, 2 \right\}, \left\{2, 1, 1 \right\}, \left\{2, 1, 1, 2 \right\}\right\}$$ is
The function $$f : [0, 3] \rightarrow [1, 29]$$ defined by $$f(x) = 2x^3 - 15x^2 + 36x + 1$$ is
If vectors $$\overrightarrow{a} = 2\hat{i} + \lambda \hat{j} + \hat{k}$$ and $$\overrightarrow{b} = \hat{i} + 2 \hat{j} + 3 \hat{k}$$ are perpendicular to each other, then value of $$\lambda$$ is
Consider the schema
Sailors(sid, sname, rating, age) with the following data
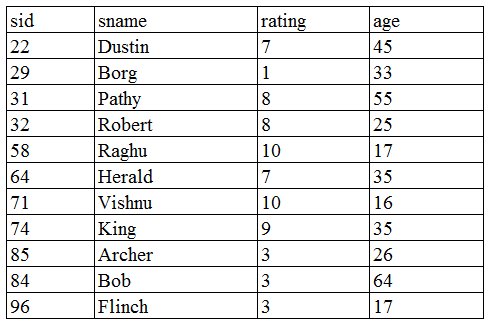
For the query
SELECT S.rating, AVG(S.age) AS avgage FROM Sailors S
Where S.age $$\ge$$ 18
GROUP BY S.rating
HAVING 1 $$<$$ (SELECT COUNT($$*$$) FROM Sailors S2 where S.rating $$=$$ S2.rating)
The number of rows returned is
Consider a table that describes the customers :
Customers(custid, name, gender, rating)
The rating value is an integer in the range 1 to 5 and only two values (male and female) are recorded for gender. Consider the query “how many male customers have a rating of 5”? The best indexing mechanism appropriate for the query is
Consider the following schema :
Sailors(sid,sname,rating,age)
Boats(bid,bname, colour)
Reserves(sid,bid,day)
Two boats can have the same name but the colour differentiates them.
The two relations
$$\rho(Tempsids, (\pi_{sid, bid}Reserves)/(\pi_{bid }(\sigma_{bname = 'Ganga'} Boats)))$$,
$$\pi_{sname}(Tempsids \bowtie Sailors)$$
If / is division operation, the above set of relations represents the query
Type IV JDBC driver is a driver
Consider the following table : Faculty(facName, dept, office, rank, dateHired)
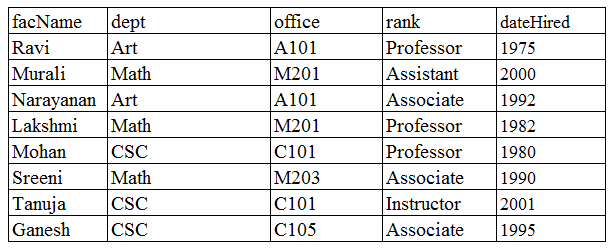
(Assume that no faculty member within a single department has same name. Each faculty member has only one office identified in office). 3NF refers to third normal form and BNCF
refers to Boyce-Codd normal form
Then Faculty is
Consider the following query :
SELECT E.eno, COUNT(*)
FROM Employees E
GROUP BY E.eno
If an index on eno is available, the query can be answered by scanning only the index if
If C is a skew-symmetric matrix of order n and X is $$n \times 1$$ column matrix, then $$X^T CX$$ is a
Consider the recurrence equation
$$T(n) = \begin{cases}2T(n - 1), & if n> 0\\1 & otherwise\end{cases}$$
Then T(n) is (in big O order)
Consider the program
void function (int n) {
int i, j, count = 0;
for (i = n/2; i <= n; i++)
for (j = 1; j <= n; j = j * 2)
count++;
}
The complexity of the program is
Match the following and choose the correct answer for the order A,B,C,D

For $$\sum = \left\{a, b\right\}$$ the regular expression $$r = (aa) * (bb) * b$$ denotes
Consider the grammar with productions
$$S \rightarrow aSb \mid SS \mid ε$$
This grammar is
Identify the language generated by the following grammar
$$S \rightarrow AB$$
$$A \rightarrow aAb \mid ε$$
$$B \rightarrow bB \mid b$$
Let $$L_1$$ be regular language, $$L_2$$ be a deterministic context free language and $$L_3$$ a recursively enumerable language, but not recursive. Which one of the following statements is false?
Let $$L = \left\{a^p \mid p is a prime \right\}$$. Then which of the following is true
Which of the following are context free?
$$A = \left\{a^nb^n a^mb^m \mid m, n \geq 0\right\}$$
$$B = \left\{a^mb^n a^mb^n \mid m, n \geq 0\right\}$$
$$C = \left\{a^mb^n\mid m \neq 2n, m, n \geq 0\right\}$$
Let S be an NP-complete problem. Q and R are other two problems not known to be NP. Q is polynomial time reducible to S and S is polynomial time reducible to R. Which of the
following statements is true?
The number of structurally different possible binary trees with 4 nodes is
Using public key cryptography, X adds a digital signature σ to a message M, encrypts $$\langle M, \sigma \rangle$$ and sends it to Y, where it is decrypted. Which one of the following sequence of keys is used for operations?
Which of the following are used to generate a message digest by the network security protocols?
(P) SHA-256
(Q) AES
(R) DES
(S) MD5
In the IPv4 addressing format, the number of networks allowed under Class C addresses is
An Internet Service Provider (ISP) has the following chunk of CIDR-based IP addresses available with it: 245.248.128.0/20. The ISP wants to give half of this chunk of addresses to Organization A, and a quarter to Organization B, while retaining the remaining with itself. Which of the following is a valid allocation of addresses to A and B?
Assume that Source S and Destination D are connected through an intermediate router R. How many times a packet has to visit the network layer and data link layer during a
transmission from S to D?
Generally TCP is reliable and UDP is not reliable. DNS which has to be reliable uses UDP because
Consider the set of activities related to e-mail
A : Send an e-mail from a mail client to mail server
B : Download e-mail headers from mail box and retrieve mails from server to a cache
C : Checking e-mail through a web browser
The application level protocol used for each activity in the same sequence is
Station A uses 32 byte packets to transmit messages to Station B using a sliding window protocol. The round trip time delay between A and B is 40 ms and the bottleneck bandwidth
on the path A and B is 64 kbps. What is the optimal window size that A should use?
A two way set associative cache memory unit with a capacity of 16 KB is built using a block size of 8 words. The word length is 32 bits. The physical address space is 4 GB. The number of bits in the TAG, SET fields are
A CPU has a 32 KB direct mapped cache with 128 byte block size. Suppose A is a 2 dimensional array of size 512 512 with elements that occupy 8 bytes each. Consider the
code segment
for (i =0; i < 512; i++) {
for (j =0; j < 512; j++) {
x += A[i][j];
}
}
Assuming that array is stored in order A[0][0], A[0][1], A[0][2]……, the number of cache misses is
A computer with 32 bit word size uses 2s compliment to represent numbers. The range of integers that can be represented by this computer is
Let M = 11111010 and N = 00001010 be two 8 bit two’s compliment number. Their product in two’s complement is
For a pipelines CPU with a single ALU, consider the following :
A. The $$j + 1^{st}$$ instruction uses the result of $$j^{th}$$ instruction as an operand
B. Conditional jump instruction
C. $$j^{th}$$ and $$j + 1^{st}$$ instructions require ALU at the same time
Which one of the above causes a hazard?
In designing a computer’s cache system, the cache block (or cache line) size is an important parameter. Which one of the following statements is correct in this context?
Consider an instruction of the type LW R1, 20(R2) which during execution reads a 32 bit word from memory and stores it in a 32 bit register R1. The effective address of the memory location is obtained by adding a constant 20 and contents of R2. Which one best reflects the source operand
A sorting technique is called stable if
Match the following and choose the correct answer in the order A, B, C

(Bounds given may or may not be asymptotically tight)
In a compact one dimensional array representation for lower triangular matrix (all elements above diagonal are zero) of size $$n \times n$$, non zero elements of each row are stored one after another, starting from first row, the index of $$(i, j)^{th}$$ element in this new representation is
Which of the following permutation can be obtained in the same order using a stack assuming that input is the sequence 5, 6, 7, 8, 9 in that order?
Quick sort is run on 2 inputs shown below to sort in ascending order
A. 1, 2, 3……n
B. n, n - 1, n - 2 …… 1
Let C1 and C2 be the number of comparisons made for A and B respectively.
Then
A binary search tree is used to locate the number 43. Which one of the following probe sequence is not possible?
The characters of the string K R P C S N Y T J M are inserted into a hash table of size of size 10 using hash function
h(x) = (ord(x) - ord(A) + 1)
If linear probing is used to resolve collisions, then the following insertion causes collision
Suppose the numbers 7, 5, 1, 8, 3, 6, 0, 9, 4, 2 are inserted in that order into an initially empty binary search tree. The binary search tree uses the reversal ordering on natural numbers i.e. 9 is assumed to be smallest and 0 is assumed to be largest. The in-order traversal of the resultant binary search tree is
A priority queue is implemented as a Max-heap. Initially it has 5 elements. The level order traversal of the heap is 10, 8, 5, 3, 2. Two new elements ‘1’ and ‘7’ are inserted into the heap in that order. The level order traversal of the heap after the insertion of the elements is
The minimum number of stacks needed to implement a queue is
A strictly binary tree with 10 leaves
What is the maximum height of any AVL tree with 7 nodes? Assume that height of tree with single node is 0.
Which one of the following property is correct for a red-black tree?
The in-order and pre-order traversal of a binary tree are d b e a f c g and a b d e c f g respectively. The post order traversal of a binary tree is
A virtual memory system uses FIFO page replacement policy and allocates a fixed number of frames to the process. Consider the following statements
M : Increasing the number of page frames allocated to a process sometimes increases the page fault rate
N : Some programs do not exhibit locality of reference
Which one of the following is true?
Consider three CPU intensive processes, which require 10, 20, 30 units and arrive at times 0,2,6 respectively. How many context switches are needed if shortest remaining time first is implemented? Context switch at 0 is included but context switch at end is ignored
A process executes the following code
for (i = 0; i < n; i ++) fork( );
The total number of child processes created is
Consider the following scheduling :

Matching the table in the order A, B, C gives
A system uses FIFO policy for page replacement. It has 4 page frames with no pages loaded to begin with. The system first accesses 50 distinct pages in some order and then accesses the same 50 pages in reverse order. How many page faults will occur?
Which of the following is false?
Which of the following is not true with respect to deadlock prevention and deadlock avoidance schemes?
Which one of the following are essential features of object oriented language?
A. Abstraction and encapsulation
B. Strictly-typed
C. Type-safe property coupled with sub-type rule
D. Polymorphism in the presence of inheritance
Which languages necessarily need heap allocation in the run time environment?
Consider the code segment
int i, j, x, y, m, n;
n = 20;
for (i = 0, i < n; i++)
{
for (j = 0; j < n; j++)
{
if (i % 2)
{
x + = ((4*j) + 5*i);
y += (7 + 4*j);
}
}
}
m = x + y;
Which one of the following is false?
Consider the following table :

Matching A, B, C, D in the same order gives :
Consider a disk sequence with 100 cylinders. The request to access the cylinder occur in the following sequence :
4, 34, 10, 7, 19, 73, 2, 15, 6, 20
Assuming that the head is currently at cylinder 50, what is the time taken to satisfy all requests if it takes 2 ms to move from one cylinder to adjacent one and shortest seek time first policy is used?
A counting semaphore was initialised to 7. Then 20 P (wait) operations and x V (signal) operations were completed on this semaphore. If the final value of semaphore is 5, then the value x will be
A 32 bit adder is formed by cascading 4 bit CLA adder. The gate delays (latency) for getting the sum bits is
We consider the addition of two 2’s compliment numbers $$b_{n - 1}b_{n - 2}.......b_{0}$$ and $$a_{n - 1}a_{n - 2}.........a_0$$. A binary adder for adding two unsigned binary numbers is used to add two binary numbers. The sum is denoted by $$c_{n - 1}c_{n - 2}.......c_{0}$$ The carry out is denoted by $$c_{out}$$. The overflow condition is identified by
Consider the function
int fun(x: integer)
{
If x > 100 then fun = x - 10;
else
fun = fun(fun(x + 11));
}
For the input x = 95, the function will return
Consider the function
int func(int num) {
int count = 0;
while(num) {
count++;
num >>= 1;
}
return(count) ;
}
For func(435) the value returned is
In IEEE floating point representation, the hexadecimal number 0xC0000000 corresponds to
Which of the following set of components is sufficient to implement any arbitrary Boolean function?
Consider the following :

Matching A, B, C, D in the same order gives.
Consider the results of a medical experiment that aims to predict whether someone is going to develop myopia based on some physical measurements and heredity. In this case, the input data set consists of the person’s medical characteristics and the target variable is binary: 1 for those who are likely to develop myopia and 0 for those who aren’t. This can be best classified as
Which of the following related to snowflake schema is true?
Consider the following C function
#include <stdio.h>
int main(void)
{
char c[ ] = "ICRBCSIT17";
char *p=c;
printf("%s", c+2[p] - 6[p] - 1);
return 0;
}
The output of the program is

